netquirks
Exploring the quirks of Network Engineering
The A to Zabbix of Trapping & Polling
Monitoring is one of the most crucial parts to running any network. There are many tools available to perform network monitoring, some of which are more flexible than others. This quirk looks at the Zabbix monitoring platform – more specifically, how you use combined SNMP polling and trapping triggers to monitor an IP network, based on Zabbix version 3.2.
The blog assumes you’re already familiar with the workings of Zabbix. However if you aren’t, the follow section gives a whistle-stop tour, from the perspective of discovering and monitoring network devices using SNMP. If you are already familiar with Zabbix, skip to The quirk section below.
Zabbix – SNMP Monitoring Overview
Zabbix can do much (much) more than I’ll outline here, but if you’re not familiar with it, I’ll describe roughly how it works in relation to this quirk.
The Zabbix application is installed on a central server with the option of having one or more proxy servers that relay information back to the central server. Zabbix has the capability to monitor a wide range of environments from cloud storage platforms to LAN switching. It uses a variety tools to accomplish this but here I’ll focus on its use of SNMP.
Anything that can be exposed in an SNMP MIB can be detected and monitored by Zabbix. Examples of metrics or values that you might want to monitor in a networking environment include:
- Interfaces states
- Memory and CPU levels
- Protocol information (neighbors IPs, neighborship status etc)
- System uptime
- Spanning-Tree events
- HA failover events
In Zabbix these metrics/values are called items. A device that is being monitored is referred to as a host.
Zabbix monitors items on hosts by both SNMP polling and trapping. It can, for example, poll a switch’s interfaces every 5 minutes and alert if a poll response comes back stating the interface is down (the ifOperStatus OID is good for this). Alternatively an item can be configured to listen for traps. If a switch interface drops, and that switch sends an SNMP trap (either to the central server or one of its proxies), Zabbix can pick this up and trigger an alert.
So how is it actually configured and setup?
The configuration of Zabbix to monitor SNMP follows these basic steps. Zabbix specific terms have been coloured red:
- Add a new host into Zabbix – including its IP, SNMP community and name. The device in question will need to have the appropriate read-only SNMP community configured and have trapping/polling allowed to/from the Zabbix address.

- Configure items for that host – An item can reference a poll (e.g. poll this device for its CPU usage) or a trap (e.g. listen for an ‘interface up/down’ trap).
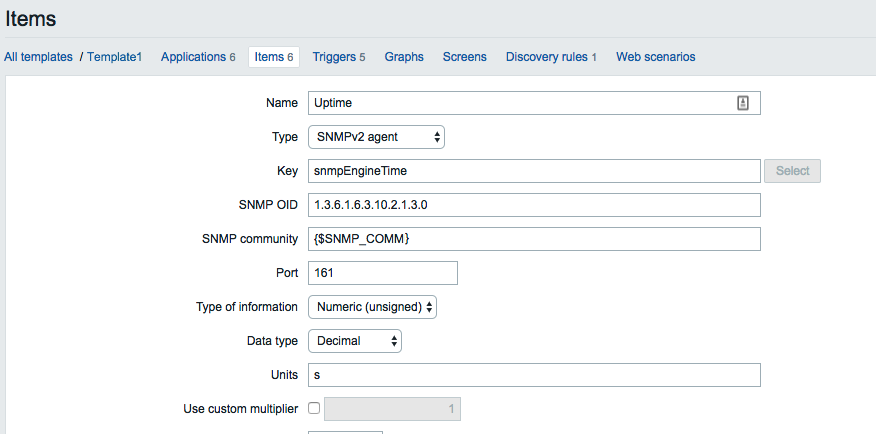
- Configure triggers that match particular expressions relating one or more items. For example a trigger could be configured to match against the ‘CPU usage’ item receiving a value (though polling) of 90 or more (e.g. 90% CPU). The trigger will then move from an OK state to a PROBLEM state. When the trigger clears (more on that below) it will move from a PROBLEM state back to an OK state.

- Configure actions that correspond triggers moving to a PROBLEM state – options depend on the severity level of the trigger but could be something like sending an email or integrating with the API of something like PagerDuty to send an SMS
This process is pretty simple on the face of things, but what happens if you have 30 switches with 48 interfaces each? You couldn’t very well configure 30×48 items that monitor interfaces states. That’s a lot of copy and pasting!
Thankfully, Zabbix has two features that allow for large scale deployments like this:
Templates – Templates allow you to configure what are called prototype items and triggers. These prototypes are bundled all into one common template. You can then apply that template to multiple devices and they will all inherit the items and triggers without them needing to be configured individually.
Low Level Discovery – LLD allows you to discover multiple items based on SNMP tables. For example if you create an LLD rule with the SNMP OID ifIndex (1.3.6.1.2.1.2.2.1.1) as the Key, Zabbix will walk that table and discover all of its interfaces. You can then take the index of each row in the table and use it to create items and triggers based on other SNMP tables. For example after discovering all the rows of the ifIndex table you could use the SNMP Index in each row to find the ifOperStatus of each of those interfaces. It doesn’t matter if the host has 48 or 8 interfaces, they will all be added using this LLD. Here’s an example of the principle using snmpwalk:

Now this is a very high level overview of Zabbix. I’m just giving a brief snapshot for those who haven’t worked with Zabbix.
Before mention the specifics of this quirk, I’ll go into a little more detail on how triggers work, since it plays a crucial role …
A trigger is an expression that is applied to an item and, as you might expect, is used to detect when a problem occurs. A trigger has two states: OK or PROBLEM. To detect when a problem occurs, a trigger uses an aptly named problem expression. The problem expression is basically a statement that describes the conditions under which the trigger should go off (e.g. move from OK to PROBLEM).
Examples of a problem expression could be “the last poll of interface x on switch y indicates it is down” or “the last trap received from switch y indicates interface x is down”.
Triggers also have a recovery expression. This is sort of the opposite of a problem expression. Once a trigger goes off, it will remain in the PROBLEM state until such time as the problem expression is no longer true. If the problem expression suddenly evaluates to false, the trigger will move to looking at the recovery expression (if one exists). At this point, the trigger will stay in a PROBLEM state until the recovery expression becomes true. The distinction to pay attention to here is that the even though the original condition that caused the trigger to go off is no longer true, the trigger remains in a PROBLEM state until the recovery expression is true. Most importantly, the recovery expression is not evaluated until the problem expression is false. Remember this for later.
So with all of that said. Let’s take a look at the quirk.
The quirk
This quirk explores how to configure triggers within Zabbix to use both polling and trapping to monitor a network device such as a router or switch.
To illustrate the idea I will keep it simple – interface states. Imagine a template applied to a switch that uses LLD to discover all of the interfaces using the ifIndex table.
Two items prototypes are created:
One that polls the interface state (ifOperStatus) every 5 minutes
and
One that listens for traps about interface states – either going down (for example listening for 1.3.6.1.6.3.1.1.5.3 linkDown traps) or coming up (for example listening for 1.3.6.1.6.3.1.1.5.4 linkUp traps)
The question is, how should the trigger be configured? We do not want to miss an interface that flaps. If an interface drops, we want the trigger to move to a PROBLEM state. But if our trigger is just monitoring the polling item and the interface goes down and comes back up within a polling cycle then Zabbix won’t see the flap.
To illustrate these concepts, I’ll use a diagram that shows a timeline together with what polling and trapping information is received by Zabbix. It uses the following legend:
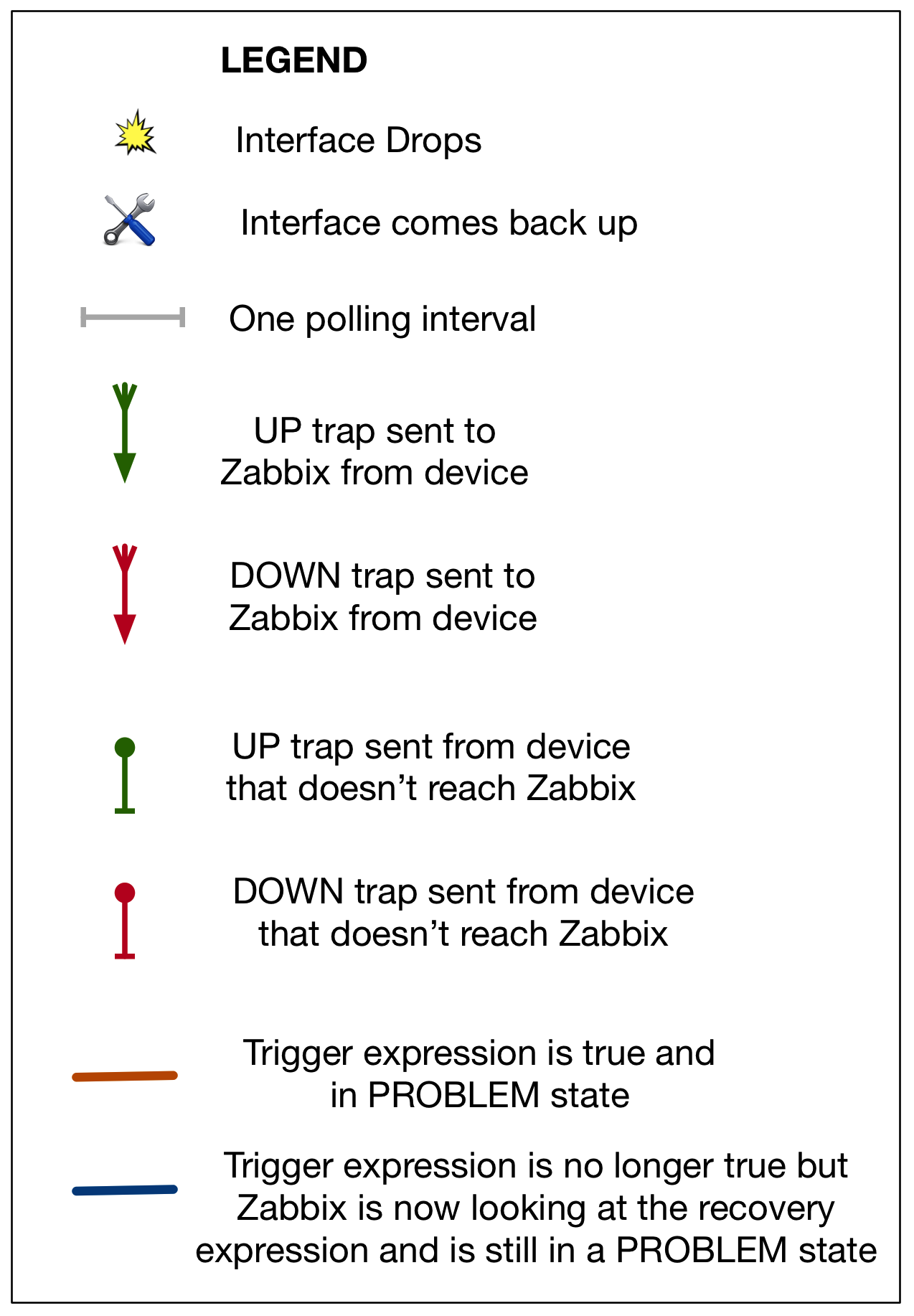
This first diagram illustrates how Zabbix could “miss” an interface flap, if it occurs between polling responses:

You can see here, that without trapping, as far as Zabbix is concerned the interface never drops.
So what if we just make our trigger monitor traps?
This also runs into trouble when you consider that SNMP runs over UDP and there is no guarantee that a trap will get through (especially if the interface drop affects routing or forwarding). Worse still, if the trap stating that the interface is down (the DOWN trap) makes it to Zabbix but the recovery trap (the UP trap) doesn’t make it to Zabbix then the trigger will never recover!

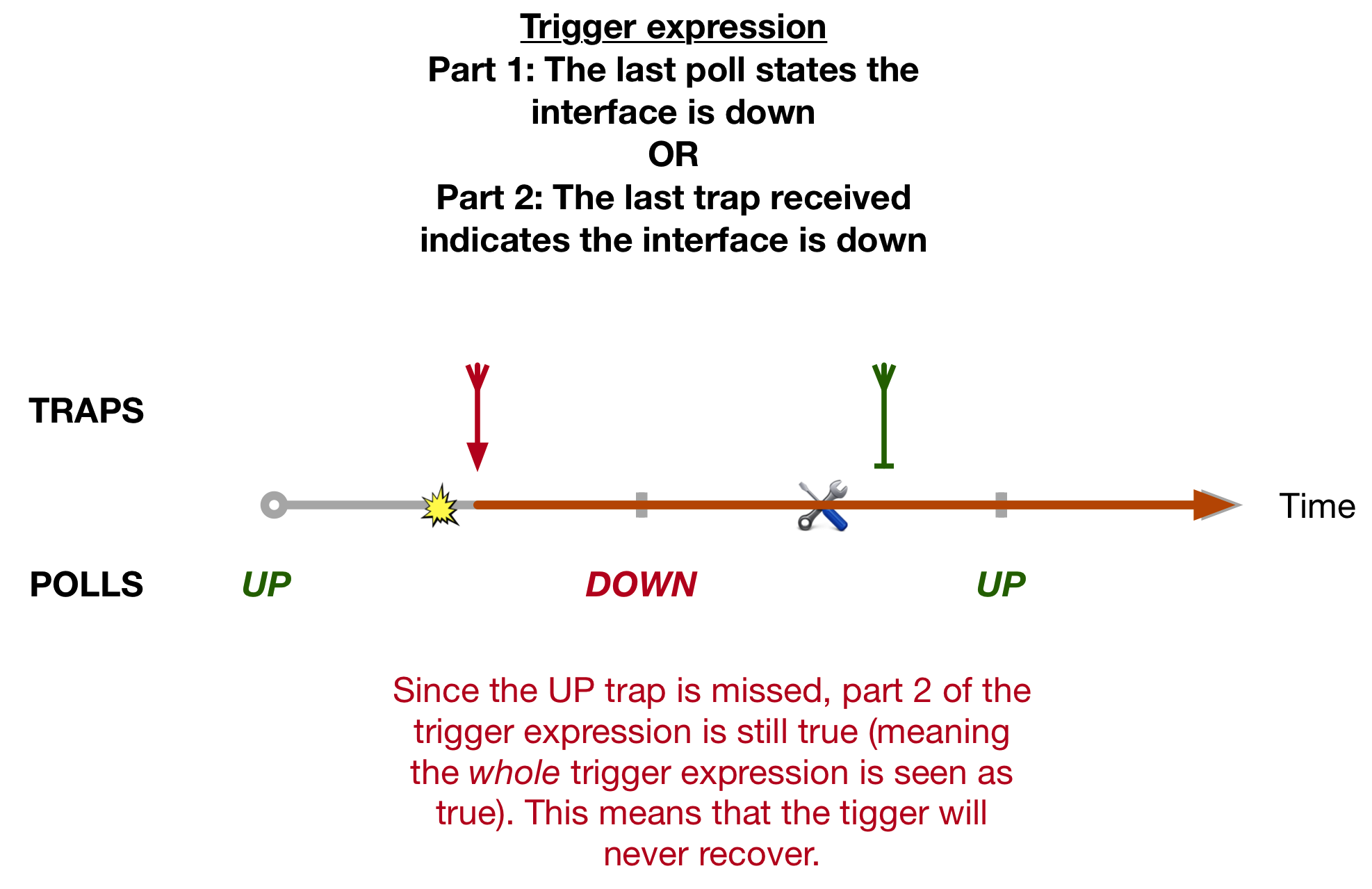
It appears that both approaches on their own have setbacks. The logical next step would be to look at combining the best of both worlds – i.e. configure a trigger that will move to a PROBLEM state if it receives a DOWN trap or a poll sees the interface as down. That way, one backs the other up. The idea looks like this:

Seems simple enough. However, the quirk arises when you realise there is still a problem with this approach …. namely, if the UP trap is missed, the trigger will still not recover.
To understand why, we’ll look at the logic of the trigger expression. The trigger expression is a disjunction – an or statement. The two parts of this or statement are:
The last poll states the interface is down
OR
The last trap received indicates the interface is down
A disjunction only requires one of the parts to be true for the whole expression to be true.
Consider this scenario: A DOWN trap is received, making the second part of the expression true. The trigger moves to a PROBLEM state. So far so good. Now image a few minutes later the interface comes back up but the UP trap is never received by Zabbix. Due to the fact that this is a disjunction, even if the last poll shows the interfaces as up, the second half of the expression is still true – as far as Zabbix is concerned that last trap it received showed the interface is down. As a result the alert will never clear (meaning the trigger will never move from PROBLEM back to OK).
There needs to be some way to configure the combination of the two that doesn’t leave the trigger in a PROBLEM state. When searching for a solution, the Recovery Condition comes into play…
The search
To focus on finding a solution we will first look at solving the missing UP trap problem. For now, don’t worry about polling.
Let’s say we a have trigger with the following trigger expression:
The last trap received indicates the interface is down
Then clearly if the trigger has gone off and we miss the UP trap when the interface recovers, this alert will never clear. So what if we combine this, using an and statement, with something else. Something else that will, no matter what, eventually become false. Since an and statement is a conjunction, both parts will need to be true. We can then use the recovery condition to control when the trigger moves back to an OK state.
We can leverage polling for this since, if the interface is down, polling will eventually detect it. So our trigger expression changes to this:
The last trap received indicates the interface is down
AND
The last poll states the interface is up
At first this might seem counter intuitive to what we looked at above, but consider that when an interface drops and the switch sends a trap to Zabbix, stating that the interface is down, the last poll that Zabbix made to the switch should have shown the interface as up – hence both statements are true and the trigger correctly moves to a PROBLEM state.
But as soon as polling catches up and detects that the interface is down, the second part of our trigger expression with become false. This makes the whole trigger expression false (since it is a conjunction) and the trigger will recover and move back to an OK state.

Now this is obviously not good. The interface is, afterall, still down! But we can use the recovery expression to control when the trigger recovers.
Remember from earlier that if a recovery expression exists, it will be looked at once the problem expression becomes false.
We can’t just configure a recovery expression on its own, until we made the above tweak, since as long as the problem expression says true the recovery expression will still be ignored.
From here the solution is simple. Our recovery expression simply states
The last two polls that we received stated the interface was up.
This means that as soon as polling detects that the interface is down, the problem statement becomes false and the recovery expression is looked at. Now, until two polls in a row detect that the interface is up, the trigger will stay in a PROBLEM state.
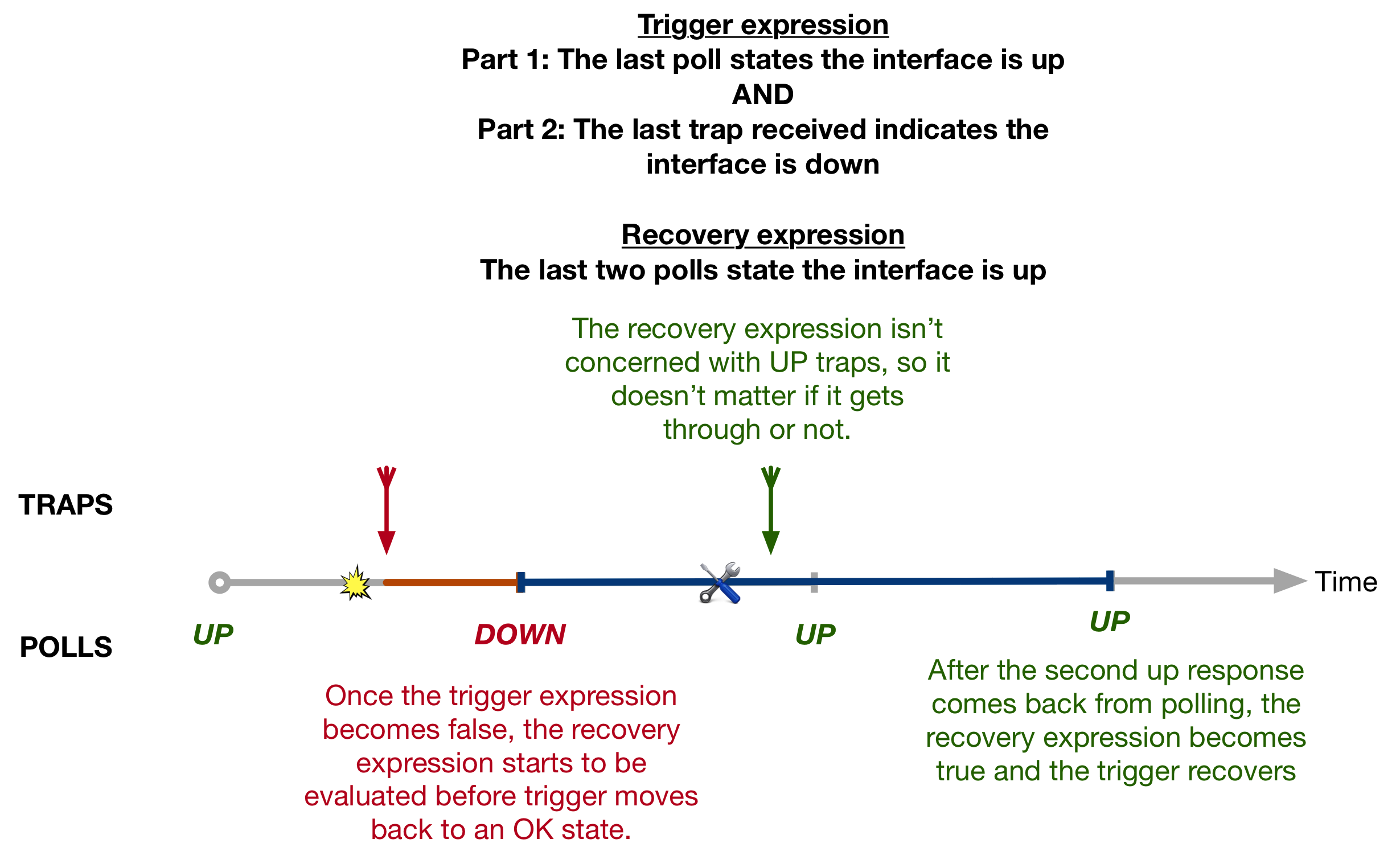
Interestingly, what we’ve essentially done is solve the missing UP trap problem, by removing the need to rely on UP traps at all! After two UP polls the trigger recovers (note the blue line of the timeline in the above diagram). You could optionally include an …or an UP trap is received to the recovery statement to make the recovery time quicker.
But there is a caveat to this case…
Consider what happens if an interface flaps within a polling cycle, meaning as far as polling is concerned, the interface never goes down. This would mean that, in the event that UP trap is missed, the problem statement will never become false. This means the trigger will never recover and we’re back to square one…

What we need is something that will inevitably cause the trigger statement to become false. Using polling doesn’t work because as we have seen, it can “miss” an interface flap.
Fortunately Zabbix has a function called nodata which can help us. The function can be found here and works as follows:
nodata(x) = 1(true) or 0(false), where x is the number of seconds where the referenced function has (true) or has not (false) received data.
To better understand this, let’s see what happens is we remove the statement The last poll states the interface is up, and replace it with one that implements this function. Our trigger statement would then become the following:
The last trap received indicates the interface is down
AND
There has been some trap data received in last x seconds (where x > bigger than the polling interval)
The second part of this conjunction is represented by trap.nodata(350) = 0 (e.g. “It is false that there has been no trap information received in the last 350 seconds” which basically means “you have received some trap information in the last 350 seconds”).
Once the 350 seconds expires that statement becomes false and the trigger moves to looking at the recovery expression. Remember our polling interval was 5 minutes, or 300 seconds.
The value x, must be at least as long as a polling interval, this will give the polling a chance to catch up as it were. Consider a scenario where x is less than a single polling interval and the interface drops just after the last poll. The nodata(x) expression will expire before the next poll comes through. When this happens, the trigger statement is false, so Zabbix will move to look at the Recovery Expression (which states that the last two polls are up). Zabbix will see the last two polls as up and trigger will recover when the interface is still down!

If x is bigger than the polling interval, polling can catch up and the trigger behaves correctly.

Now that we have solved this we can reintroduce polling into the trigger. Remember that the initial DOWN trap could still be missed. We saw that there were problems when trying to integrate polling and trapping together into a trigger’s Problem Expression, but we can easily create a single poll-based trigger.
This trigger can be relatively simple. The Problem Expression simply states that the last two polls show the interface as down. There doesn’t need to be a Recovery Expression, since when the trigger sees two UP polls it can recover without problems.
Now we’ve got another problem though. We don’t want two triggers to go off for just one event. Thankfully Zabbix has the feature of dependence. If we configure the poll-based trigger to only move to a PROBLEM state if the trap-based trigger is not in a PROBLEM state, then this poll-based trigger effectively acts as a backup to the trap-based one. I’ll explore the exact configuration of this in the work section.
Once this has been configured you’ll have a working solution that supports both polling and trapping without having to worry about alerts not triggering or clearing when they should. Let’s take a look at how this configured on the Zabbix UI.
The Work
In this section I will show screenshots of the triggers that are used in the aforementioned solution. I haven’t shown the configuration of the LLD or of any corresponding Actions (that will result in email or text messages being sent), but Zabbix has excellent documentation on the how to configure these features.
First we’ll look at the trapping configuration:

The Name field can use variables based on OIDs (like ifDesc and ifAlias) that are defined in the Low Level Discovery rule to make the trigger contain meaningful information of the affected interface. The trigger expression references the trap item that listens for interface down traps.
The trap item itself will look at the log output produced by the Zabbix snmptrapd process passing traps through an SNMPTT config file. This process parses incoming traps and creates log entries. Trap items can then match against these logs.
In this case, the item matches against log entries containing the string
“Link up on interface {#SNMPINDEX}” – which is produced when a linkup trap is received
Or
“Link down on interface {#SNMPINDEX}”}” – which is produced when a linkdown trap is received
where {#SNMPINDEX} is the index of the table entry for the ifIndex table.
In this trigger expression the trap item is referenced twice. Firstly, it matches a trap item that has the “link down” substring in it (i.e. if a down trap is received for that ifIndex). Secondly, it uses the noData = 0 (false) function – this means that “some trap data has been received in the past 350 seconds”.
This matches the pseudo-expression we have above:
The last trap received indicates the interface is down
AND
There has been some trap data received in last x seconds (where x > bigger than the polling interval).
If a trap is received stating the interface is up, the trap item will no longer contain the string “link down” – rather it will contain “link up”, so the first part will become false.
Alternative, if no trap is received in 350 second (either UP or DOWN) the second half of the AND statement will become false. The polling interval is less that 350 seconds so if the up trap is missed polling will have the chance to catch up.
Either way, the trigger will eventually look at the recovery expression. The recovery expression references the ifOperStatus item and the ifAdminStatus item.
The recovery expression basically states:
IF
The last two polls of the interface operational state is up
OR
The last poll of the administrative state of the interface is down (i.e. someone has issued ‘shutdown’ on the interface, if it’s an interface on a Cisco device)
THEN recover.
The second half of the disjunction is used to account for scenarios where an engineer deliberately shut down an interface – in which case you would not want the alert to persist.
Next we’ll look at the polling trigger:

This one is much simpler. The trigger will go off if the last two polls of the interface indicate that the operational state is down (2) AND the admin state is up (1) – meaning that it hasn’t been manually shutdown by an engineer.
Finally, the last trick to making this solution works is in the dependencies tab of this trigger prototype:

In this screen, the trap-based trigger has been selected as a dependency for the poll-based trigger. This means that the poll-based trigger will only go off if the trap-based trigger hasn’t gone of.
So that’s the work involved in configuring the actual triggers and it brings us to the end of this quirk. It demonstrates how to combine polling and trapping into Zabbix triggers to allow for consistent and correct alerting.
Zabbix has a wide range of functions and capabilities – far more than what I’ve outlined there. There may very well be another way to accomplish the same goal so as usual, any thoughts or idea are welcome.

Very good article, but I have a question.
How do you define item protypes I am trying to replicate your configuration…, if you could paste a screnshot of it, would be perfect.
LikeLike
Hi Marcos. Thanks for the kind words 🙂 Item Prototypes are created under Discovery Rules. If you’re using Templates, you can follow these steps:
1. Go to Confutation -> Templates -> click on your template.
2. Then click on Create Discovery Rule.
3. Create the discover rule (usually specifying the SNP table you want to walk) and save.
4. You’ll then be taken back to previous menu and will see your new Discovery Rule.
5. You’ll notice that each of your Discovery Rules will have Items, Triggers and Graphs menus, just like the Template itself.
6. Click on the Item prototypes menu and create the item under there. The output will look analogous to the item configuration screenshot in the blog (the second image from the top)
Zabbix has some very good documentation here: https://www.zabbix.com/documentation/3.2/manual/discovery/low_level_discovery
Hope that helps
LikeLike
Hello Steven, the problem I have is that in the Discovery Rule I want to use this type: SNMP Trap but it does not appear.
Does It mean that I can not create a Discovery Rule with SNMP trap data?
The scenario is as follows.
I get SNMP traps on my Zabbix with this information:
SNMPv2-SMI::enterprises.111.15.3.1.1.14.1 type=4 value=STRING: “problemTbsp10iDct”
SNMPv2-SMI::enterprises.111.15.3.1.1.24.1 type=4 value=STRING: “excpddbadm02”
SNMPv2-SMI::enterprises.111.15.3.1.1.21.1 type=4 value=STRING: “NIXP”
And I need to create Items with this information:
“problemTbsp10iDct”
“excpddbadm02”
“NIXP”
Can I do that?
LikeLike
Hi mate,
I’m not sure I completely follow. It sounds like you might be wanting to parse incoming SNMP traps and then use the Zabbix trap Item to match against them.
If that’s the case, you can edit the snmptt.conf file (usually found in /etc/snmp/ or similar). SNMPTT parses an incoming trap and you can edit this file to control how it appears in the log files. The trap Item can then be created under a discovery rule to look at these logs.
Documentation to setup edit the snmptt.conf file can be found here: http://www.snmptt.org/docs/snmptt.shtml#SNMPTT.CONF-Configuration-file-format
If you have any other queries about setting up Zabbix you can ask here at the Zabbix forums: https://www.zabbix.com/forum
I hope that’s useful. Best of luck.
LikeLike